Gradient descent III: SGD for Polyak-Łojasiewicz functions
October 2023In the preceding note on stochastic gradient descent we proved some convergence guarantees for functions satisfying strong convexity assumptions. Now, we move on to a more realistic setting. A differentiable function is -Polyak-Łojasiewicz[1] (-PL for short) if it is bounded below and if for every ,
What is really impressive is that most results on gradient descent or SGD transfer directly from strongly convex functions to PL functions... but PL functions need not even be convex! This is a great leap forward for optimization, and it's quite a recent finding.
Two important examples of PL functions which are not convex are
where is any set and the distance is the euclidean one.
when and the smallest singular value of the Jacobien is uniformly bounded away from zero, ie . This roughly says that is locally invertible, and « uniformly so ». In this case is -PL.
These examples show that PL functions form a really wider class than (strongly) convex functions. On the other hand, they need not have a unique minimizer, which is the case for strongly convex functions. Indeed, (1) implies that any critical point () has . In other words, local minima are not unique at all, but they are all global, see (b) in the Figure below[2].
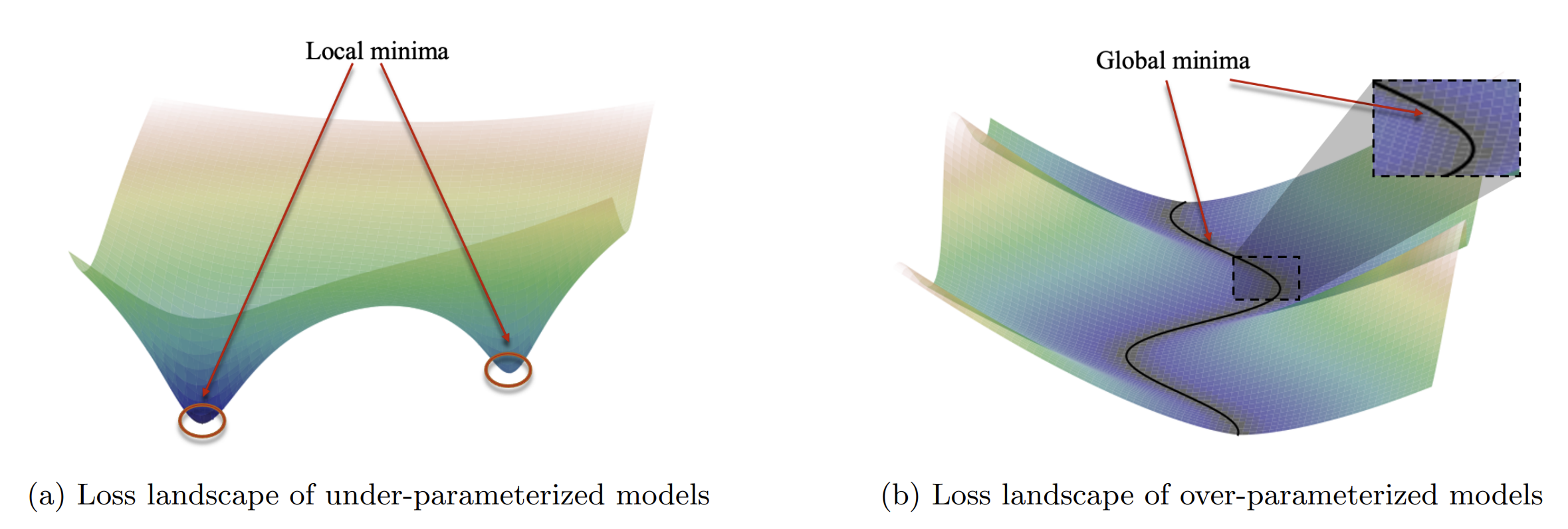
Consequently, optimization algorithms will not find minimizers of but they will search for the minimum value of instead. Just as for strongly convex functions, there is a general convergence result for vanilla Gradient Descent, but I'll only present the corresponding result for SGD. That is, we are now in the minimization of a function assuming the shape
where the are PL functions. The SGD is given by the updates
where for each step , the index is independent of and . For future reference, we recall that is -smooth if , see the note on GD.
If all the are -PL and -smooth, and if the step size is smaller than , then
where is the local discrepancy of around its minimal value:
The difference between this and the classical GD result is the additional term featuring . Strikingly, when all the have the same minimal value (ie ), this term disappears since . This situation is called interpolation. It does imply that all the can reach their minimal value at the same time. One might be tempted to check how this relates to the local variance introduced in the case of strongly convex functions. It turns out[3] that if all the are -smooth, (i) in general, ; (ii) if the are -strongly convex, then . So in the case of strongly convex functions, these two parameters measure the same thing.
Proof
It is once again the same kind of tricks as for GD and SGD, but now we directly apply them to instead of applying them to . For simplicity, we will suppose that the minimum value of is zero, ie .
Writing the fact that is -smooth (since if all the are -smooth), then using the definition of the SGD update rule, we have
We now take conditional expectations with respect to . Since , we get
Now we need to estimate the latter expectation and for this, we use the following elementary lemma.
The proof is left as an exercise. Incidentally, this fact sheds some light on the PL-condition. In fact, PL functions satisfy the opposite inequality up to a constant. This is why PL functions efficiently replace the strong convexity assumption.
Apply (9) to the -smooth function to get
Now, plug these inequalities in (8) to get
We did not use the PL condition – but not for much longer. When reversed, (1) tells us that . We plug this into the last inequality, reorganize terms, take expectations, and we get
It's over now. The first factor is and we chose the stepsize precisely so that . The final recursion reads
This is once again a classical recursion of the form and it is easily leveraged to , hence
Discussion
Minibatch SGD. In this note and the preceding one I chose the simplest SGD version, the one where is a sum and we choose one of the functions to estimate the full gradient. The same proof can be adapted to more complicate settings, such as mini-batches where at each step we draw a random batch of indices uniformly at random on and estimate the gradient with . The main difference will be on the definition of the discrepancy which needs to be adapted (it's straightforward).
Noisy SGD. The other variant of SGD is when we have access to a noisy estimate of the gradient, say for simplicity where is an independent small Gaussian noise. I don't know if there are results for this (typically, they shall relate to the mixing time of the Langevin dynamics).
Local PL functions. The PL assumption is considerably more realistic than strong convexity. PL functions need not be convex and need not have a unique minimizer. However, the absence of non-global local minima can be considered highly unrealistic, especially when dealing with neural networks. One possible workaround would be to replace the global PL condition with local ones. What happens when we only assume that functions are locally PL? Many results were obtained in this line: this one or this one for proximal gradient. More recently this paper by Sourav Chatterjee goes in the same direction. However these results are only valid for classical gradient descent. There are no similar results for SGD.
Neural Networks. Applying such results to neural networks remains a moot point. The main argument is that the loss landscape for NNs in the infinite width regime (and for certain initializations), the loss landscape is almost quadratic. The paper by Liu, Zhu, Belkin is a wonderful read for anyone interested in the topic. They essentially study the small singular values of the differential of a NN – these singular values are the spectral values of the Neural Tangent Kernel, and the NTK is supposed (under certain circumstances) to be… almost constant. Hence, NNs are almost PL.
References
These three notes on GD and SGD were mostly taken from the wonderful survey by Guillaume Garrigos and Robert Gower, here. Guillaume proofread this note. Most of the remaining errors are due to him.
[1] The Polish Ł is actually pronounced like the French « ou » or the English « w ». So Łojasiewicz sounds like « Wo-ja-see-yeah-vitch ». Among well-known Polish names with this letter, there's also Rafał Latała, Jan Łukasiewicz or my former colleague Bartłomiej Błaszczyszyn whose name is legendarily hard to pronounce for Westerners.
[2] Figure extracted from the Liu, Zhu, Belkin paper.