🏋🏼 Heavy tails IV: cascades of events
June 2026Sixty stocks jump in the same minute — coincidence or not? In many fields where we study the occurrence of simultaneous events in time, it turns out that the number of simultaneous events is often small, but can also be dramatically big, with a typically heavy-tail distribution. There is a nice explanation for this phenomenon, coming from the theory of random avalanches –- a fancy name for Galton-Watson processes. This post explains the connection.
Price jumps in financial markets
ook at the prices of stocks (say, in the S&P500) and examine how many of them experience a jump at the same time (say, within the same hour or minute). This is called co-jump analysis. Here are two plots taken from an insightful paper:
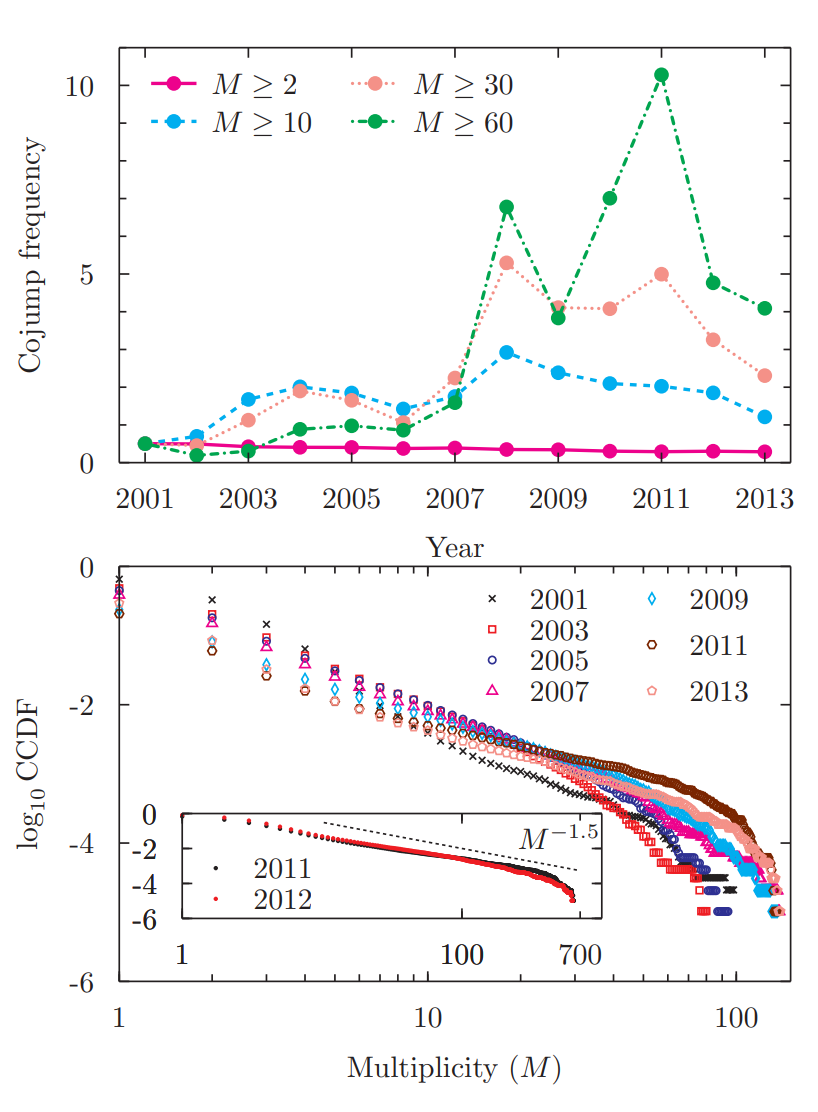
On the top, you see the number of minutes, in every year, where there was a co-jump. For example the green line counts the minutes where more than 60 stocks jumped at the same time. The most interesting plot is the second one, plotting the distribution of the sizes of the co-jumps. The scale is logarithmic, and clearly this distribution looks heavy tailed, perhaps with an index of , which would mean that the number of co-jumps of stocks is roughly of order . As we’ll see, other papers estimate the tail to be rather .
Why should these types of events exhibit a heavy-tail behaviour? There is a very simple answer: there is a "cascading" happening behind the jumps. One jump occurs somewhere: say, the price of goes up first. Then this jump triggers a few jumps in related companies, like . The jump for triggers in turn another jump at . Maybe the jump at Microsoft didnt trigger anything, but in turn the jump at triggers a jump in . And so on, the initial event cascades into the network, until the contagion stops.
This kind of cascading effect (« random avalanches ») naturally leads to a heavy-tailed distribution for the total number of events that happened in the end. This is what we are going to prove.
Galton-Watson processes and the total population law
The total number of events in a cascade described as earlier is well captured by Galton-Watson processes. In a GW process, one starts with a random initial number of events, say . Then each of these events triggers a random number of extra events: if is the number of events triggered by element , then the total number of events that were triggered by the initial generation is
This is the size of the second generation, and the process goes on: if at generation there are events, then at the next generation one has
where the are all iid with the same distribution , called progeny distribution. In the end, the total number of events which happened is
where it is perfectly possible that this is infinite! For example, if then every events triggers at least one other event, so it can very well happen that .
There’s an infinite litterature on GW processes, but we’ll be interested in the distribution of , namely for every . We’re going to prove that this distribution is heavy-tailed, indeed.
Dwass’s representation of the total population law
Proof. We assume for simplicity (one initial event); the general case is the same up to a convolution with the law of .
Take a cascade with total size . List the events in the order they were discovered in the cascade: first the initial event, then the events it triggered, then the events triggered by those, and so on. If is the number of events triggered by the -th event in this list, we get a sequence of nonnegative integers. Clearly : there are events and triggering relations between them. Conversely, any sequence with this sum encodes a cascade if and only if it never "runs out of events" before time . Writing , this means
For instance, if then the initial event triggers nothing and the cascade stops at size , so cannot be larger than .
Thus is the probability that satisfies these conditions. Now comes the trick. For fixed with , consider all cyclic rotations of the sequence.
The lemma is purely combinatorial; a one-line proof goes by comparing, for each rotation, the first time its partial sum drops below the diagonal. Since the total sum is , exactly one rotation stays above.
Back to the cascade. If , no rotation of can satisfy the condition above, so . If , the cyclic lemma says that exactly one rotation does satisfy it. Because the are iid, all rotations have the same probability, hence
The phase transition
It is a classical topic in probability courses to study the transition happening in GW trees. I’m not going to prove it, but only to state it, because we will see the transition appear in the sequel. Let be the mean of the progeny distribution. It is intuitive that if , then since every event triggers, on average, less than one extra event, then the cascade should stop at some point; and if then there is a serious chance that the cascade never stops and goes on forever. This is indeed a theorem.
Extinction. If , then and .
Critical case. If , then but .
Survival. if , then .
In the survival case, the Kesten-Stigum theorem additionnally states that
Exponential growth. If , then either the population dies, or it survives, and then there is a (random) constant such that .
Subexponential growth. Otherwise, if , then almost surely.
We will not use the Kesten-Stigum result, I only stated there because I like it. But we’ll see that the critical transition at has its own importance when studying the total population size.
The CLT approximation
So now, we can estimate how heavy is the tail of . In fact, is just a random walk, a sum of iid random variables, and we know how to deal with them. If and , the CLT says that
Let us approximate . Clearly, we have
where we set . How could we approximate this probability? Well, there are two cases. If , then there is a nonzero probability of the cascade going on and on up to infinity. In many real-world situations, this would be called apocalyptic; it falls in a totally different typology of rare events. We would rather be interested in the case where . Indeed, in this regime, we see that
but . It is well known that a Gaussian with standard deviation will fall with high probability in an interval . So if has order , we could approximate with the CLT; this happens when is very close to being critical, ie . Otherwise, if , then falls within the regime of rare events and large deviations.
The critical case and the CLT
If , then we are examining the probability of to be close to 0, which is well in the bulk of the distribution. This is roughly the Gaussian density,
This approximation is actually rigorous: one would need to use a variant of the CLT called the local-limit theorem to make it work.
The non-critical case and large deviations
If , then we are examining the probability of a Gaussian with std of order , taking values of order . This lies in the large deviation regime, where we study the occurrence of very unlikely events. Cramér’s theorem says that
where is the rate function.
Conclusion
Going back at (4), we obtain an approximation for in the near-critical regime . Noting , it can be framed as follows.
This is not exactly heavy-tailed in the classical sense, but it is already with smaller tails than the Gaussian: it is actually a Gamma distribution. When the mean progeny attains the critical value , then and one obtains a typically heavy-tailed behaviour, , with tail index as observed for the financial price co-jumps!
As a conclusion, we see that the total number of events that can happen in a cascade is heavy-tail near criticality. This is exactly the point: when the mean progeny is very small, nothing special happens in the sense that the total number of events is subexponentially distributed. But when the mean progeny reaches the critical point, the tails become fatter, until eventually they become Pareto with tail index .
You don’t need to be critical to have heavy tails
It can feel a little bit unsatisfying that (11) is not strictly speaking heavy-tailed for, say, . There is however a nice argument, which I found in Appendix E1 of this excellent paper by Rudy Morel, which justifies heavy tailedness. It consists in supposing that the mean progeny parameter is itself random, say uniformly distributed in an intervall containing 1, like . In this case,
We can perform this integral easily: by a change of variables, we see that
If is small, say , then the integral there is close to , a constant, and overall we get
This would give a tail index with index . By choosing different distributions for , one could easily get any heavy tail index .
References
On financial price jumps, this paper and this paper are very insightful.
This paper is a little bit old but still interesting.
Branching processes and GW trees are a canonical (beyong classical) topic in probability theory; among all the things that were written, I like these notes by Zhan Shi.