The Kelly criterion, crypto exchange drama, and your own utility function
November 2022Better is bigger
There's been a lot of fuss recently on the FTX collapse and the spiritual views of his charismatic (?) 30-year old founder Sam Bankman-Fried (SBF). In a twitter thread, SBF mentioned his investment strategy and his own version of a plan due to the mathematician John L. Kelly. Further discussions (especially this one by Matt Hollerbach) pointed that he missed Kelly's point. Sam's misunderstanding prompted him to go for super-high leverage, which resulted in very risky positions – and in fine, a bankrupcy.
Fixed-fraction strategies
Here's the setting: you are in a situation where, for epochs, you can gamble money. At each epoch you can win with probability , and if you win you get times your bet. If you lose (with proba ) you lose times your bet. Therefore, if you bet , your expected gain is
And if you bet , your expected gain is .
John L. Kelly, in his 1956 paper, asked and solved the following question:
Your investment strategy is that, at each step, you bet a fraction of your current wealth – the fraction is constant over time.
What is the optimal ?
His solution is this famous Kelly criterion, otherwise dubbed Fortune's formula in the bestseller of the same name by W. Poundstone, and became part of the history of the legendary team around Shannon who more or less disrupted some casinos in Las Vegas's Casino's in the 60s. Here's a short presentation.
Small formalization
We set or according to the outcome of the -th bet and we note the total number of wins before . Starting with an initial wealth of (million), at each epoch we bet a constant fraction of our total wealth. Then, our wealth at epoch is
where .
Going full degenerate
A no-brain strategy[1] to maximize the final gain is to compute and then optimise in . Using independence,
and now we seek which maximizes this function. Clearly is increasing or decreasing according to or ; indeed, let us suppose that (the expected gain is positive), the nobrain strategy consists in : at each epoch, you bet all your money. The expected gain is
It is exponentially large: even for a very small expected gain of and epochs you get : you nearly tripled your wealth! But suppose that (that is, you win or lose what you bet); should you have only ONE loss during the epochs, you lose everything. The only outcome of this strategy where you don't finish broke is where all the bets are in your favor, with proba . To fix ideas, if and , . For it drops to less than .
Indeed, here are some sample paths: for and various values of I plotted the evolution of your wealth (starting at 1) for 100 epochs –- averaged over 50 runs.
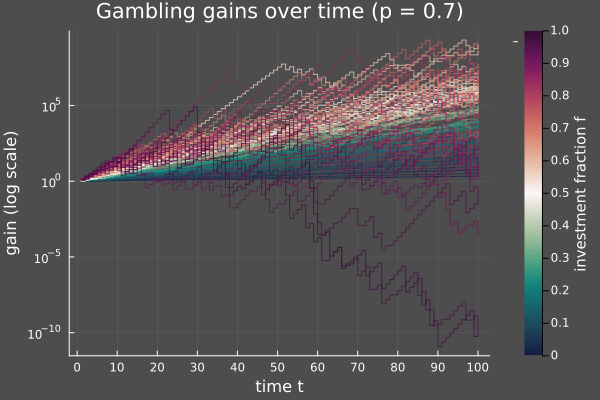
You clearly see that having very close to (violet paths) yield the absolute worst results, in practice. So what's the best value? It seems to fit somewhere inside the yellow-orange region –- that is, between 0.4 and 0.7.
The Kelly strategy
Kelly noticed that, if the number of epochs is large, the portion of winning bets should be close to , that is we roughly have by the Law of Large Numbers. Consequenly,
Now you want to maximize this to get the optimal . This is equivalent to finding the max of
and after elementary manipulations the optimal fraction is
Here it should be understood that if is negative or greater than , we clip it to 0 or 1. For most cases though, will be between and . For instance if it is equal to .
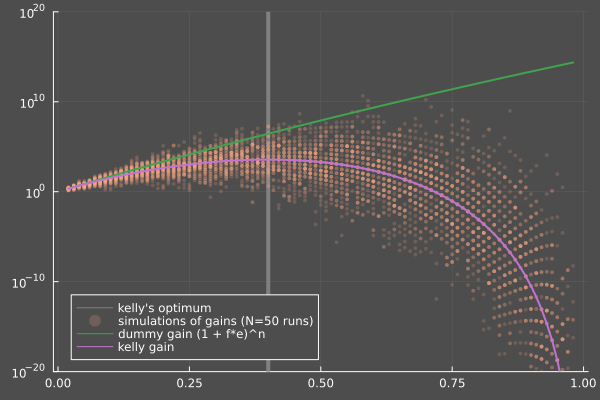
Here's an illustration with . The purple line corresponds to the mean gain predicted by Kelly and it's maximized for . Orange dots are samples for this specific .
Is there a paradox?
We adopted two plans for finding the maximizing the final wealth, but they don't match. The no-brain approach seems theoretically sound while in the Kelly approach, the approximation (5) might seem suspicious; but the numerics clearly show that for you alwost always end up with a greater wealth than with close to 1. Kelly's approach is justified by arguing that Kelly does not optimize the same objective as the nobrainer; indeed, Kelly rigorously maximizes the logarithm of the gain:
which is exactly times (6). How would one justify maximizing the logarithm of the wealth instead of the wealth? Well, one potential justification is with utility functions, that thing from economy –- but this is indeed not a good justification.
Utility functions
If you win 1000€ when you have only, say, 1000€ in savings, it's a lot; but if you win 1000€ when you already have 1000000€, it means almost nothing to you. The happiness you get for each extra dollar increases less and less; in other words, the utility (I hate the jargon of economists) you get is concave. Your utility function could very well be logarithmic, and the Kelly criterion would tell you how to maximize your logarithmic utility function.
This interpretation is the one put forward by SBF in his famous thread, and it is mostly irrelevant, as already noted by Kelly himself.
The twist is that with utility functions, you could justify any a priori strategy . They're not a good tool for understanding people's behaviour or elaborating investment strategies. You can even exercice yourself by finding, for any fixed , a concave utility function such that the maximum expected utility is attained at .
That's more or less how SBF justified his crazy over-leverage strategy, by saying that his own utility function was closer to linear ( than logarithmic (. In his paper, Kelly actually argues that rather than taking his criterion as the best possible, we should take it as an upper limit above which it should be completely irrational to go. SBF, on the other hand, used this analysis to justify all-or-nothing strategies which resulted in, well, quite bad an outcome.
The Kelly criterion is a an empirical rule
Actually, the Kelly criterion relies on empirical gain maximization.
In a more realistic setting where you could play a Kelly gambling game, you wouldn't know , but you probably would have access to a history of data from past players; that is, you would have a long historical series where is the outcome of the -th bet (win or lose). If you had played this game at these times, with an -fixed fraction strategy, you would exactly have won
where is the total number of past wins. But then, the optimal which maximizes this empirical gain would precisely be (do the maths):
with the natural estimators for and . And if is large enough, the LLN gives us and .
Beyond gambling
The nice part about the Kelly criterion as an empirical gain maximization rule is that you can apply it well beyond the simplistic win/lose framework. For example, should you invest in Stock, you have at your disposition a time series of returns for ; say, is the daily return of some stock. Starting with 1, your gain with an -fixed fraction strategy would have been . Your best fixed-fraction strategy would then maximize the function
Of course, this is interesting only when some returns can be extreme. If is close to 0, the above function is just approximated by where since , and the optimal would always be if and 1 otherwise.
Concluding remarks
Always look for geometric returns, not arithmetic.
The Kelly criterion is over-simplistic. Quantitative investment books are full of variants.
If you justify your actions by your utility function, chances are you're just out of control.
Don't invest in crypto now
Notes
[1] the « full degen » strategy, as Eruine says