🏋🏼 Heavy tails III: Kesten's theorem
November 2023Motivation: ARCH models
In 2003, Robert F. Engle won the Nobel prize in economy for his innovative methods in time-series analysis; to put it sharply, Engle introduced ARCH models into economics. In his seminal 1982 paper (30k+ citations), he wanted to model the time-series representing the inflation in the UK. Most previous models used a simple autoregressive model of the form , where is an external Gaussian noise with variance and a "forgetting" parameter. The problem with these models is that the variance of the inflation at time knowing the inflation at time , that is , is simply the variance of , which does not depend on .
Engle wanted a model where the conditional variance would depend on : there are good reasons to think that volatility is sticky. The model he came up with (equations (1)-(3) in his paper) is simply
In other words, the variance of given is . This is the simplest of Auto-Regressive Conditionally Heteroscedastic (ARCH) models. Upon squaring everything in (1), the equation becomes
This is a linear recursion in . In the paper, Engle introduced a few variations and crafted statistical methods to estimate the parameters and their significance.
If converges in distribution towards a random variable , then (2) shows that and must have the same probability distribution, where is an , independent of . This is an instance of a very general kind of equations, called affine distributional equations: they are equations of the form
where are random variables independent of . It turns out that these equations are generally impossible to solve. However, a theorem of Harry Kesten states, perhaps not so intuitively, that the law of any solution must have a heavy tail: in contrast with, say, Gaussian distributions, for which taking extremely large values (« shocks ») has an exponentially small probability, heavy-tailed distributions can take large values with polynomially small probability, which is… not so rare at all!
Here is a small simulation over periods of time and parameters . The histogram indicates that seems to have heavy tails, that is, the probability of observing a unusually large value is polynomially small (and not exponentially small).
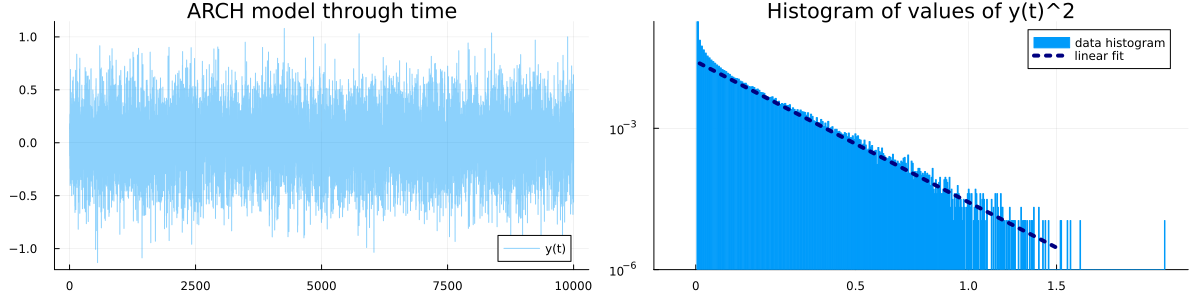
This is one of Kesten's most famous results, published in 1973 in Acta Mathematica.

Kesten's theorems
From now on, we'll study the solutions of the equation
where is a random variable over , is a random matrix and a random vector, both independent of . The goal is to present Kesten's theorem, which states that on certain conditions on and , the solution must have heavy tails; that is, decreases polynomially fast, and not exponentially fast as for Gaussian variables. This result is somehow mind-blowing in its precision, since we have access to the exact tail exponent.
A full, rigorous proof would be packed with technicalities; I'll only show a simili-proof in dimension , which, although not being complete, was sufficiently clear and idea-driven to convince me that Kesten's result holds. I'm also including a simili-proof of the Renewal theorem, which might be of independent interest.
One-dimensional case
For simplicity, we restrict to the case where are independant and have a density with respect to the Lebesgue measure. In general, it is not obvious that solutions to (4) exist, but a former result by Kesten states that it is the case if .
Kesten's theorem (1973).
(i) Assume that almost surely and that there is an such that Then, there are two constants such that when , (ii) The same result holds if can take positive and negative values, and in this case .
Sketch of proof in the 1d case
I'll only sketch the proof ideas in the subcase of (i) where in addition, is nonnegative. In this case, we can safely assume that is nonnegative by conditionning over the set . We set ; our final goal is to prove that converges towards some constant when , the case being identical.
The recursion (4) shows that . However, if is very large, we could guess that is close to . This is the origin of the first trick of the proof, which is to artificially write
Let us note the first term on the right:
For the second term, we can express it in terms of by using :
Now, here comes the second trick: the change of measure. We assumed that , hence we can define a probability distribution by , and the expression above becomes . Overall, we obtain that is a solution of the following equation:
If is the density of under the measure , this equation becomes where denotes the convolution operator. Such equations are called convolution equations and they can be studied using classical probability theory. The main result of Renewal Theory, exposed later below, shows that
if is « directly Riemann integrable »;
and if , which is the same thing as ;
then there is only one solution to this equation, and more crucially it satisfies
If , as we assumed, then , because is a nonzero positive function so its integral is nonzero. Consequently,
This is equivalent to , as requested. There is, however, a serious catch: to apply the main Renewal theorem we need to check the two conditions listed above. The second one is nothing but an assumption. However, the first one needs to be "directly Riemann integrable", which is indeed very difficult to check. I won't do this part at all[1].
Multi-dimensional case
In the multi-dimensional case, a similar theorem holds. One can find in the litterature a host of different settings regarding the random matrix and the random vector ; for simplicity I'll stick to the case where is positive definite almost surely, has all entries nonnegative almost surely, and have densities with respect to the Lebesgue measure. The multi-dimensional analogue of will now be
where is the operator norm. We also introduce the Lyapounov exponent, which is the equivalent of :
Kesten's theorem in any dimension. Assume that and that there is an such that Then, solutions of (4) exist, and is heavy-tailed in any direction; in other words, for any nonzero , there is a constant such that
The proof is much more technical without any new ideas.
Renewal theory in less than one page
Let be a continuous probability distribution on . Our goal is to show how renewal theory can be used to study convolution equations, represent their solutions with a probabilistic model, and draw consequences on their asymptotic behaviour. We are interested in finding such that
where is some function. Noting , we recognize a convolution between the function and the measure , and the equation is simply . Upon noting a random variable with distribution , we can also represent this equation as
But if this equation is satisfied for some , then plugging it into yields
and so on, with iid copies of . The following theorem follows by iterating this trick infinitely.
The name "renewal process" comes from the fact that the are considered as occurence times of events. The are thus waiting times between the events. Renewal theory is interested in processes like the number of events before time .
It is quite rare that the representation theorem yields the explicit solution . One would need to compute the expectation of the series, which is most cases can be tedious. But this representation gives access to the whole toolbox of limit theorems in probability, and in particular, laws of large numbers, which translate into exact asymptotics for . That's the key renewal theorem.
« Directly Riemann integrable » is the true equivalent of « Riemann integrable », but for functions defined over or the half-line. It states that the Riemann sums over the whole domain (they are indeed series, not sums, in contrast with the classical definition) converge toward the same limit.
The intuition is pretty clear. In Blackwell's version, is nothing but the number of in the interval . If the size of each jump is roughly then the number of jumps in this interval should be proportional to the length of the interval divided by ; Blackwell's theorem says that this is true when . Note that in this case and .
By linearity, Blackwell's version extends to (22) at least for piecewise constant functions with bounded support. To extend to wider functions, a limiting argument is needed, and this is where direct Riemann integrability comes into play.
We can very well have in this theorem but for simplicity I'll stick to the finite case.
The theorem is also valid when is not necessarily positive, but on the condition that . This version is due to Athreya et al. (1978).
A full, readable proof can be found in Asmussen's book. I'll probably write a note on this topic, some day.
References
Kesten's original paper, really hard to read.
Goldie's paper, which both simplified and generalized Kesten's proof (the proof in this note is Goldie's). Hard to read too.
An excellent book on the topic by Buraczewski, Damek and Mikosch. This is where I learned the proof of Kesten's theorem. It's very well written.
Another excellent book with a chapter on the Renewal Theorem, by Asmussen.
| [1] | indeed, there's a catch. It is not possible to directly prove that is directly Riemann integrable. Instead, what Goldie did is that he mollified the problem by convoluting with a mollifier , proved the equivalent for this version, then sent to zero. |